Benchmarks
Test dataset
Section titled “Test dataset”55.8M paired-end reads (SRR24827378, whole-genome bisulfite sequencing). All outputs verified byte-identical (decompressed) across all core counts via md5 checksums.
At a glance
Section titled “At a glance”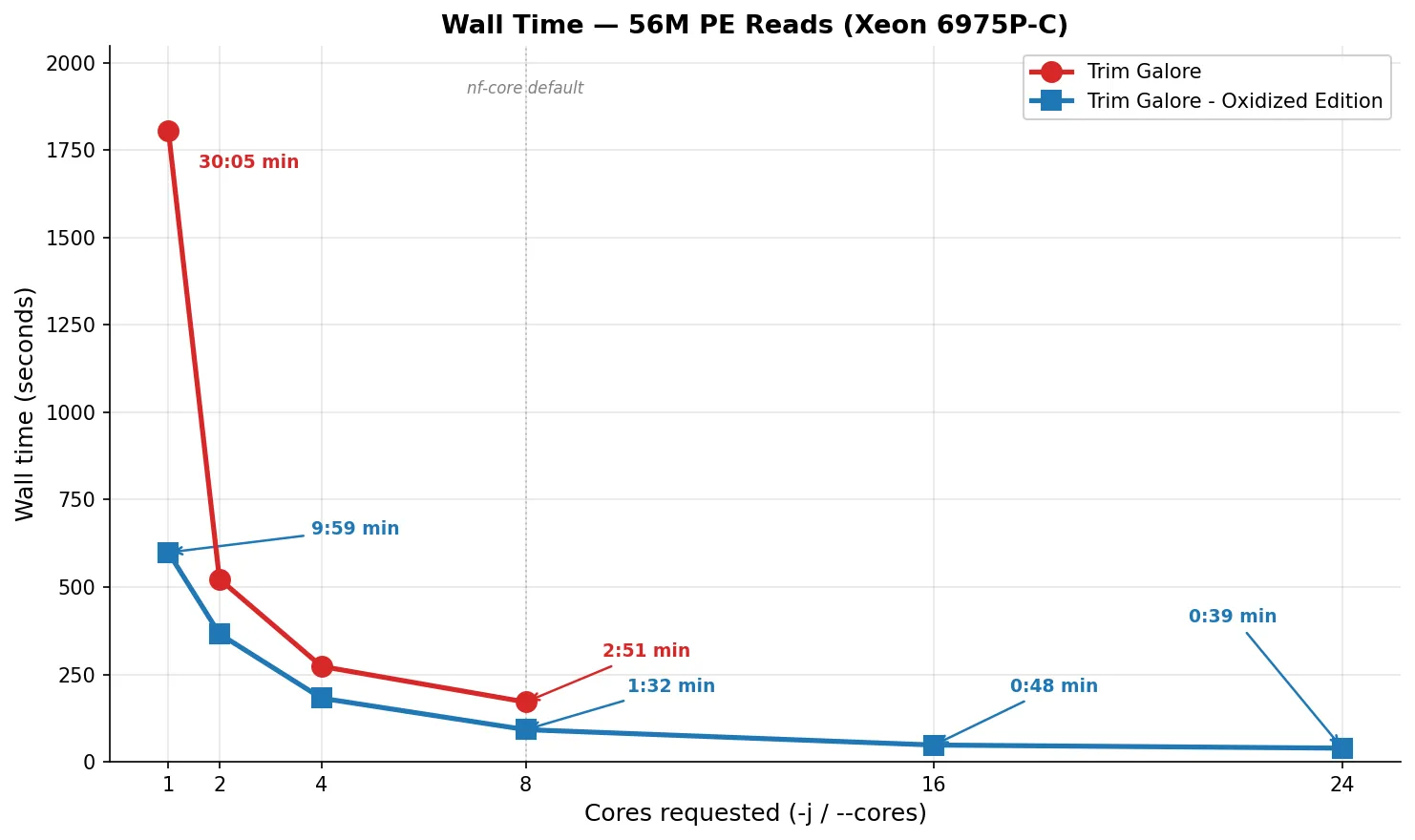
Server benchmark: Intel Xeon 6975P-C (32 vCPU)
Section titled “Server benchmark: Intel Xeon 6975P-C (32 vCPU)”Trim Galore (Perl 5.38 + Cutadapt 5.2 + pigz 2.8 + igzip/ISA-L for decompression)
Section titled “Trim Galore (Perl 5.38 + Cutadapt 5.2 + pigz 2.8 + igzip/ISA-L for decompression)”-j | Wall time | CPU time | Memory | Threads (observed) |
|---|---|---|---|---|
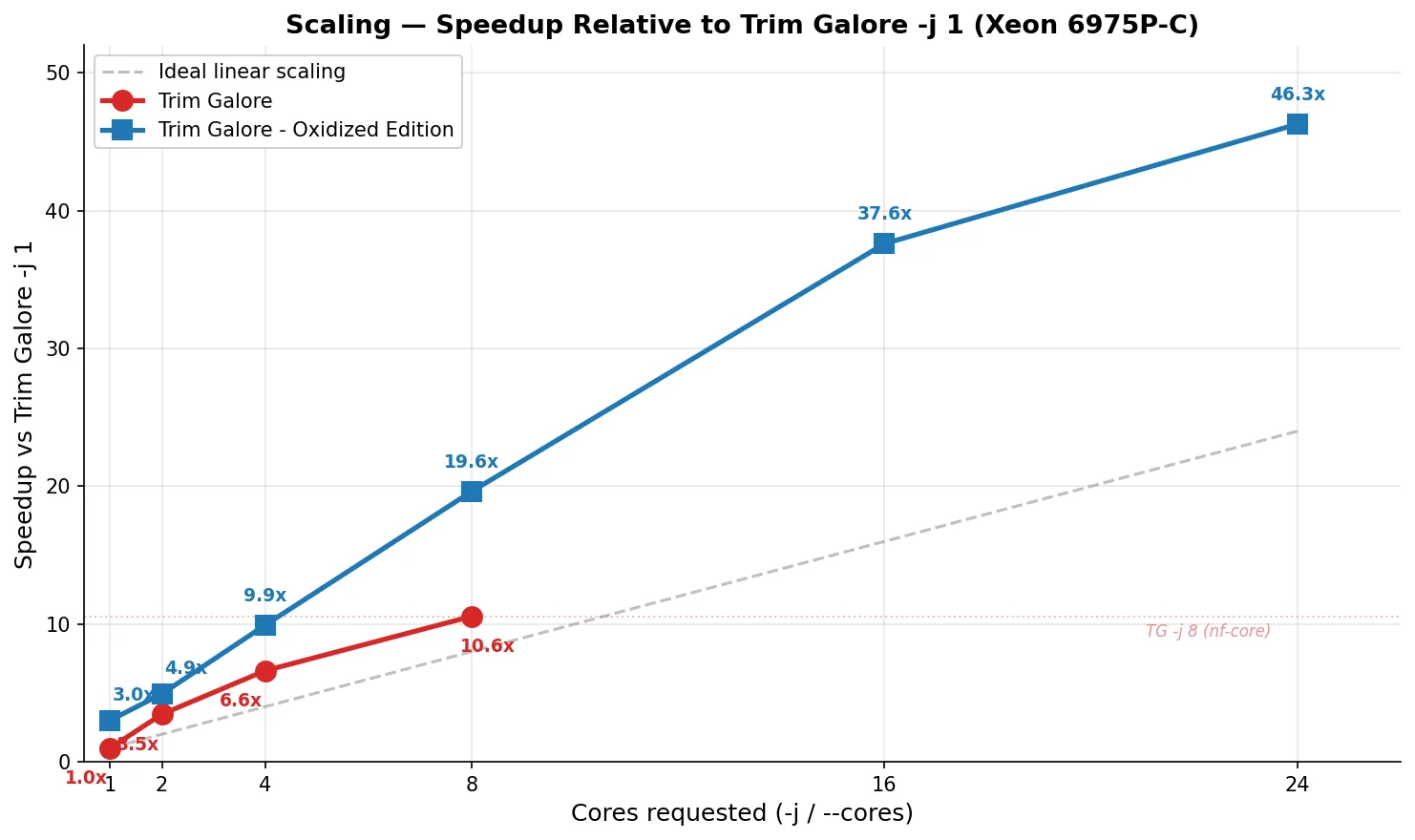
| 1 | 30:05 (1,805s) | 3,001s | 21 MB | up to ~6 |
| 2 | 8:43 (523s) | 2,009s | 39 MB | up to ~9 |
| 4 | 4:33 (273s) | 2,010s | 42 MB | up to ~15 |
| 8 | 2:51 (171s) | 2,040s | 61 MB | up to ~27 |
Trim Galore Oxidized Edition (Rust, zlib-rs)
Section titled “Trim Galore Oxidized Edition (Rust, zlib-rs)”--cores | Wall time | CPU time | Memory | Threads (deterministic) |
|---|---|---|---|---|
| 1 | 9:59 (599s) | 599s | 5 MB | 1 |
| 2 | 6:06 (366s) | 780s | 43 MB | 6 |
| 4 | 3:02 (182s) | 771s | 62 MB | 8 |
| 8 | 1:32 (92s) | 784s | 100 MB | 12 |
| 16 | 0:48 (48s) | 814s | 171 MB | 20 |
| 24 | 0:39 (39s) | 874s | 157 MB | 28 |
Head-to-head (same core count)
Section titled “Head-to-head (same core count)”| Cores | TG wall | Oxidized wall | Wall speedup | TG CPU | Oxidized CPU | CPU savings |
|---|---|---|---|---|---|---|
| 1 | 1,805s | 599s | 3.0x | 3,001s | 599s | 5.0x |
| 4 | 273s | 182s | 1.5x | 2,010s | 771s | 2.6x |
| 8 | 171s | 92s | 1.9x | 2,040s | 784s | 2.6x |
Production comparison: nf-core default (--cores 8)
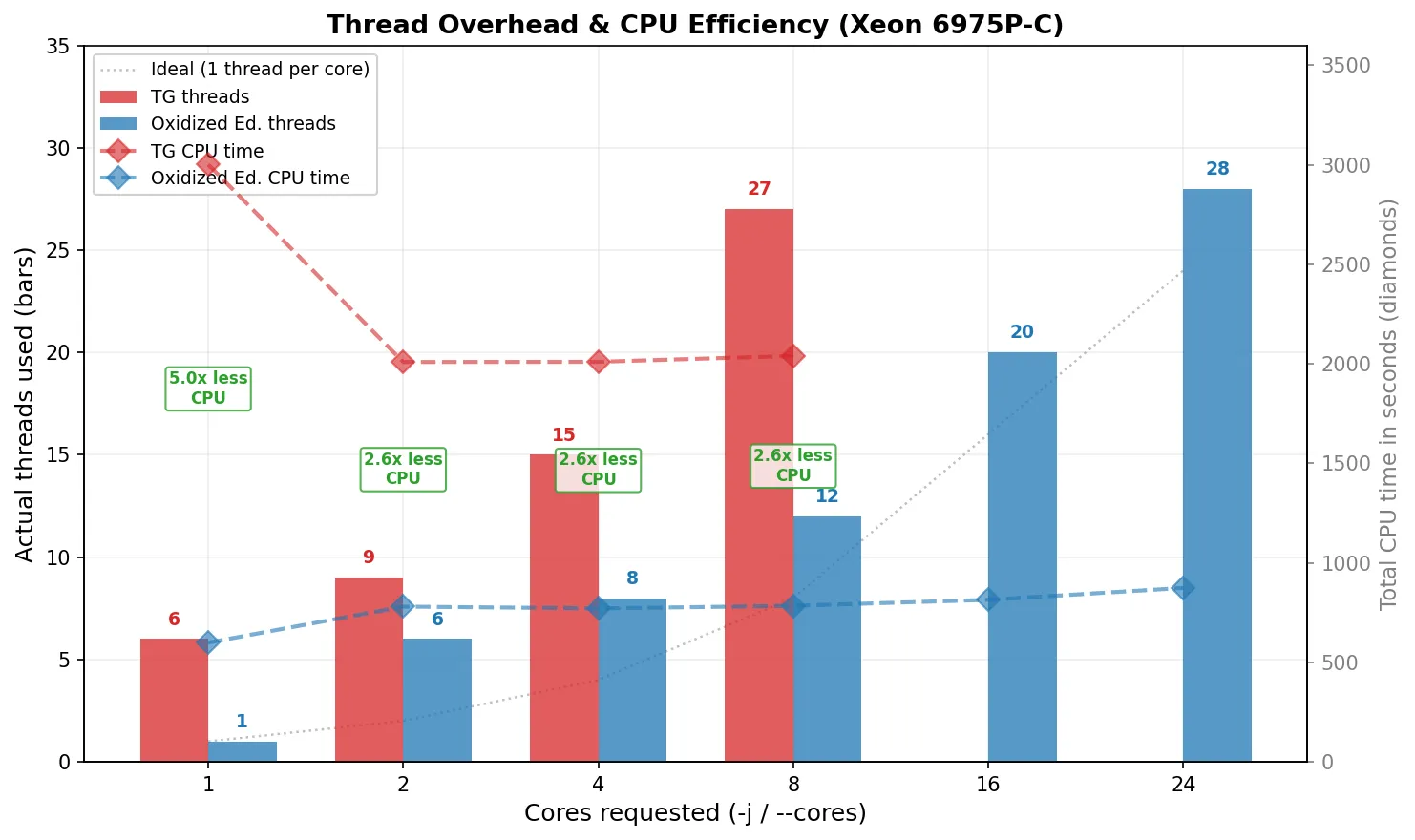
Section titled “Production comparison: nf-core default (--cores 8)”In nf-core pipelines, Trim Galore is typically allocated 12 CPUs (process_high) and run with -j 8 (the module subtracts 4 for overhead). With -j 8, TG spawns up to ~27 threads across Cutadapt workers, pigz compression, and pigz/igzip decompression. nf-core installs TG from bioconda, which includes igzip (Intel ISA-L) for decompression.
TG -j 8 | Oxidized --cores 4 | Oxidized --cores 8 | Oxidized --cores 24 | |
|---|---|---|---|---|
| Wall time | 171s | 182s | 92s (1.9x faster) | 39s (4.4x faster) |
| CPU time | 2,040s | 771s (2.6x less) | 784s (2.6x less) | 874s (2.3x less) |
| Threads | up to ~27 | 8 | 12 | 28 |
| Memory | 61 MB | 62 MB | 100 MB | 157 MB |
Three ways to read this:
- Same speed, fewer resources: Oxidized
--cores 4(8 threads) matches TG-j 8(up to ~27 threads) in wall time, using 2.6x less CPU and a third of the threads. - Same resources, much faster: Oxidized
--cores 8uses 12 threads (fewer than TG's ~27) and is nearly twice as fast. - Comparable thread budget, 4.4x faster: Oxidized
--cores 24(28 threads) vs TG-j 8(up to ~27 threads). Finishes in 39 seconds vs 171 seconds, using 2.3x less CPU.
Laptop benchmark: Apple M1 Pro (10 cores)
Section titled “Laptop benchmark: Apple M1 Pro (10 cores)”Trim Galore (Perl 5.34 + Cutadapt 4.9 + pigz)
Section titled “Trim Galore (Perl 5.34 + Cutadapt 4.9 + pigz)”-j | Wall time | CPU time |
|---|---|---|
| 1 | 27:04 (1,624s) | 2,536s |
| 2 | 13:50 (830s) | 2,741s |
| 4 | 7:15 (435s) | 2,868s |
Trim Galore Oxidized Edition
Section titled “Trim Galore Oxidized Edition”--cores | Wall time | CPU time | Speedup vs TG -j 1 |
|---|---|---|---|
| 1 | 11:46 (706s) | 695s | 2.3x |
| 2 | 7:16 (436s) | 908s | 3.7x |
| 4 | 3:46 (226s) | 936s | 7.2x |
| 6 | 2:35 (155s) | 957s | 10.5x |
| 8 | 2:03 (123s) | 994s | 13.2x |
Cost and CO₂
Section titled “Cost and CO₂”CPU time is what cloud providers bill for and what drives energy consumption. The Oxidized Edition uses 2.3 to 5x less CPU time than Trim Galore for the same job:
| Scenario | TG CPU time | Oxidized CPU time | CPU savings |
|---|---|---|---|
| Single-threaded | 3,001s | 599s | 5.0x |
| 8 cores (nf-core default) | 2,040s | 784s | 2.6x |
On AWS at $0.05/vCPU-hour, trimming 56M PE reads costs roughly $0.028 with TG vs $0.011 with Oxidized (at 8 cores) — a 2.6× saving per sample. Across a 1000-sample cohort that scales to **$28 vs ~$11**, with proportional savings in carbon footprint and shared-cluster CPU-hour pressure.
Methodology
Section titled “Methodology”- Timing: All wall time, CPU time, and peak memory measured via
/usr/bin/time -v. - Thread counts (TG): Observed via
psduring execution. These are approximate peak values, as threads are spawned across three independent subprocesses (Cutadapt, pigz, pigz/igzip) whose lifetimes may not fully overlap. - Thread counts (Oxidized): Deterministic from the architecture: exactly N+4 threads for
--cores N(N workers + 2 decompressors + 1 batcher + 1 writer), or exactly 1 thread for--cores 1. - igzip: The bioconda Trim Galore installation includes igzip (Intel ISA-L) for fast single-threaded decompression. Benchmarks were re-run with igzip to match the nf-core production environment; the difference was <1% (decompression is not the bottleneck; compression is).
- Outputs verified: All outputs were confirmed byte-identical (decompressed) between TG and Oxidized across all core counts via md5 checksums.
For the architectural reasons behind the numbers (single-pass vs three-pass architecture, worker-pool parallelism, thread-budget breakdown), see Threading model.